
Over langzaam denken: waarom we Andri bouwden om te overwegen
De meeste AI-systemen denken één keer en antwoorden dan. Andri is gebouwd om te delibereren: meerdere denkpassen, eigen werk controleren, en opnieuw beginnen als een redenering niet houdt.
Ik herinner me een ervaren advocaat die werkte aan een echt lastig probleem. Dit was jaren geleden, lang voordat ik iets met AI deed.
Wat me trof was niet haar scherpte, hoewel ze scherp was. Het was de bereidheid om ongelijk te hebben. Ze werkte bijna een uur aan één lijn van argumentatie, trok jurisprudentie erbij, bouwde een structuur op, en toen... stopte ze gewoon. Zei dat het niet zou houden. Begon helemaal opnieuw vanuit een andere hoek.
De meeste mensen die ergens goed in zijn, willen er ook goed in lijken. Zij leek daar niet mee bezig. Ze wilde het goed hebben, en goed hebben betekende bereid zijn om een uur werk weg te gooien als het nergens toe leidde.
Daar denk ik nu veel over na.
Het ding met AI
Zo werkt de meeste AI: je stelt een vraag, het genereert een antwoord. Eén keer door het model. Klaar.
En kijk, dit is vaak prima. Voor documenten samenvatten, tekst vertalen, feitelijke vragen beantwoorden, het werkt verrassend goed. Het model heeft miljoenen voorbeelden gezien, herkent patronen, je krijgt je antwoord.
Het probleem ontstaat wanneer je echt moet redeneren. Wanneer het eerste plausibele antwoord misschien fout is. Wanneer je je werk moet controleren, of een andere aanpak moet proberen, of moet erkennen dat je in de war bent.
Het model kan dat allemaal niet. Het weet niet of zijn antwoord goed is. Het produceert gewoon output met dezelfde zelfverzekerde vloeiendheid, of de onderliggende redenering nu klopt of niet.
Dit stoort me voor juridisch werk specifiek. Recht is een domein waar zelfvertrouwen en correctheid slecht samengaan. Ik heb juniors memo's zien schrijven die volledig overtuigend klinken maar iets cruciaals missen. Seniors lezen dezelfde feiten en zien meteen drie problemen. Niet omdat ze per se slimmer zijn, maar omdat ze geleerd hebben wantrouwig te zijn tegenover makkelijke antwoorden.
Kun je een systeem bouwen dat geleerd heeft wantrouwig te zijn tegenover zijn eigen makkelijke antwoorden? Die vraag bleef maar terugkomen.
Wat we gelezen hebben
Ik moet eerlijk zijn: de wetenschap hier is jong. Veel van wat nu veelbelovend lijkt, kan verkeerd uitpakken. Maar er zijn bevindingen die hebben beïnvloed hoe we hierover denken.
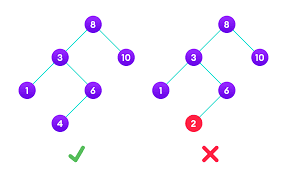
Er is onderzoek naar wat er gebeurt als je taalmodellen vraagt om te plannen over meerdere stappen. Niet alleen een vraag beantwoorden, maar navigeren naar een doel via een reeks beslissingen. De consistente bevinding is dat single-pass generatie uit elkaar valt. Het model redeneert over losse stappen prima, maar verliest samenhang over het geheel. Raakt vast in lussen. Vergeet beperkingen die het eerder vaststelde.
Wat helpt is het model een proces geven om zorgvuldiger na te denken. Laat het een stap zetten, kijken wat er gebeurde, begrip bijstellen, opnieuw nadenken. Onderzoekers noemen dit "ReAct": redeneren en handelen (Reasoning + Acting), in een lus met observaties. Succespercentages schieten omhoog op problemen waar single-pass benaderingen faalden.
Er is verwant werk over "Tree of Thought", het idee dat wanneer een probleem meerdere mogelijke aanpakken heeft en je niet weet welke werkt, je systematisch moet verkennen. Probeer pad A, kijk waar het heengaat. Loop vast, ga terug, probeer pad B. Snoei doodlopende wegen.
Dit is gewoon... hoe mensen moeilijke problemen oplossen? Het is hoe die advocaat werkte. Het is hoe wetenschappers onderzoek doen. Het inzicht uit de AI-literatuur is dat het niet vanzelf ontstaat uit training. Je moet het inbouwen.
Niets hiervan is definitief. Dit zijn gecontroleerde experimenten op smalle taken. We weten niet echt hoe goed het generaliseert. We nemen een gok.
Waarom dit uitmaakt voor recht
Recht heeft eigenschappen die dit bijzonder relevant maken.
Juridische problemen vertakken. Je volgt niet één draad. Je overweegt wanprestatie, verjaring, causaliteit, schade, procedure, allemaal tegelijk, en ze werken op ingewikkelde manieren op elkaar in. Het juiste antwoord hangt vaak af van het verkennen van meerdere paden voordat je kunt zien welke het sterkste is.
Juridisch redeneren is adversarieel. Wat je ook beargumenteert, iemand gaat het aanvallen. Als je AI één keer nadenkt en een antwoord produceert, kan dat antwoord zwaktes hebben die een menselijke tegenstander direct ziet. Het punt van deliberatie is niet alleen het juiste antwoord vinden. Het is je antwoord stresstesten voordat iemand anders dat doet.
Juridisch werk omvat lange taken. Een conclusie van antwoord opstellen is niet één vraag. Het is de vordering begrijpen, geschilpunten identificeren, elk punt onderzoeken, een antwoord structureren, opstellen, consistentie controleren, citaties verifiëren. Elke stap voedt de volgende. Fouten stapelen op.
We hebben systemen gebouwd die iets hiervan doen. Systemen die onderzoek plannen, evalueren wat ze vinden, beslissen of ze dieper moeten graven. Systemen die tegengestelde perspectieven simuleren. Systemen die lange documenten aankunnen zonder de draad kwijt te raken.
Maar ze falen nog steeds op manieren die ons verrassen. Dat is de eerlijke waarheid. De wetenschap van betrouwbaar redeneren is moeilijk.
Wat we eigenlijk proberen
Er is een verleiding bij het bouwen van AI-producten om te optimaliseren voor demo's. Een systeem dat één keer nadenkt en een vloeiend antwoord produceert ziet er indrukwekkend uit. Voelt als magie.
Een systeem dat delibereert, dat soms terugkeert, dat soms zegt "wacht even, laat me dit anders bekijken", is minder spectaculair. Maar het is eerlijker over hoe moeilijke problemen worden opgelost.
Ik denk dat dit verder gaat dan productkwaliteit. Het gaat over wat voor relatie mensen kunnen hebben met AI.
Als systemen altijd zelfverzekerd klinken, stoppen gebruikers ofwel helemaal met ze te vertrouwen (en verifiëren alles zelf, wat het doel ondermijnt) of ze vertrouwen wanneer ze dat niet zouden moeten doen, en fouten glippen erdoor. Geen van beide is goed.
Als systemen hun redenering tonen, onzekerheid signaleren, hun werk controleren, dan kunnen gebruikers anders met ze omgaan. Ze kunnen zien waar het systeem zeker is en waar het tast. Ze kunnen ingrijpen op beslismomenten.
Dat is wat we proberen te bouwen. Geen orakel. Een tool dat redeneert op een manier die je kunt volgen en tegenspreken.
Ik weet oprecht niet of we daar gaan komen. De technische uitdagingen zijn echt. We nemen risico's die verkeerd kunnen uitpakken.
Maar het lijkt het juiste om te proberen.
Hoe dan ook
Ik wil voorzichtig zijn niet te veel te claimen. Het onderzoek waar we op bouwen is veelbelovend maar niet definitief. Onze systemen zijn beter dan simpelere aanpakken op veel taken maar falen nog steeds regelmatig. Wat werkt in gecontroleerde experimenten vertaalt niet altijd.
Wat ik wel kan zeggen is dat we een bewuste keuze hebben gemaakt om systemen te bouwen die meer dan één keer nadenken. We deden het omdat juridisch werk (vertakkend, adversarieel, langlopend) het lijkt te vereisen. En omdat we denken dat vertrouwen tussen advocaten en AI afhangt van de AI die eerlijk is over zijn proces, niet alleen vloeiend in zijn output.
Of iets hiervan klopt, zal de tijd leren. De mensen die elke dag met Andri werken zijn de echte test.
Als het hen helpt beter werk te doen, als het problemen opvangt voordat ze ertoe doen, als het vertrouwen verdient door betrouwbaarheid in plaats van het te eisen door zelfverzekerdheid, dan heeft het gewerkt.
Zo niet, dan leren we iets en proberen we het anders. Dat is ook hoe deliberatie eruitziet, denk ik.
Wil je zien hoe dat er in de praktijk uitziet? Probeer Andri.
Lees ook: waarom juridische AI moet denken, niet alleen reageren en hoe onze agentische architectuur werkt in de praktijk. Of bekijk hoe Advocatenkantoor Blokziel dagelijks met deze aanpak werkt.
Papers die ons denken hebben gevormd: Aghzal et al. over padplanning en ruimtelijk-temporeel redeneren, Long over Tree-of-Thought, en Yao et al. over Tree of Thoughts. Voor toegankelijke uitleg van deze technieken is de Prompting Guide uitstekend. De vertaling van academische bevindingen naar productiesystemen omvat veel keuzes die van ons zijn, niet van hen.